※제로베이스 데이터 취업스쿨 11기 수강 중
📗 23일차 공부 내용 요약

1. 데이터 살펴보기 : 서울시 범죄 데이터
2. Pandas pivot_table
3. 데이터 정리하기 : 다중 컬럼에서 특정 컬럼 제거
4.Python 모듈 설치 : pip 명령, conda 명령
5.Google Map API 설치
6.Python의 반복문 : list comprehension, iterrows()
7.Google Maps 이용한 데이터 정리
📖 23일차 공부 내용 자세히

1. 데이터 살펴보기 : 서울시 범죄 데이터
천단위 구분 제거하고 숫자로 인식하기 → thousands = ‘,’
- 1000단위 이상 숫자들은 콤마(,)를 사용하고 있어 문자로 인식될 수 있음
- 천단위 구분(thousands = ',')이라고 알려주면 콤마를 제거하고 숫자형으로 읽는다
crime_raw_data = pd.read_csv(
'../data/02. crime_in_Seoul.csv',
thousands = ',',
encoding = 'euc-kr')
NAN 값 확인하기
- isnall() : NaN 값이 있다면
- notnall() : NaN값이 없다면
crime_raw_data[crime_raw_data['죄종'].isnull()]
crime_raw_data[crime_raw_data['죄종'].notnull()]2. Pandas pivot_table
데이터프레임.pivot_table()
- index = [ ] inex 지정, 여러 개 지정 가능
- values = [ ] values 지정, 여러개 지정 가능
- columns = [ ] 분류 지정
- aggfunc = [ np,sum, np.mean ] 연산 지정, 여러개 가능
- fill_values = 0 NaN에 대한 처리 지정
- margin = True 총계
df.pivot_table(
index = ['Manager', 'Rep', 'Product'],
values = ['Price', 'Quantity'],
aggfunc = [np.sum, np.mean], #연산, 디폴트는 평균이다
fill_value = 0, #NaN 에 대한 처리 지정
margins = True #총계 추가
)
3. 데이터 정리하기
다중 컬럼에서 특정 컬럼 제거 → droplevel( )
- pivot_table을 적용하면 column이나 index가 다중으로 잡힌다
- 데이터프레임.columns.droplevel([제거할 컬럼 인덱스])
crime_station.columns = crime_station.columns.droplevel([0,1])

6.Python의 반복문
list comprehension
for n in range(0,10):
print(n**2)
#위 코드를 한 줄로 : list comprehension
[ n**2 for n in range(0,10 )]
7.Google Maps 이용한 데이터 정리
구글 맵 임포트 하기
import googlemaps
gmaps_key = '***'
gmaps = googlemaps.Client(key=gmaps_key)
컬럼추가와 NaN 값으로 채우기
crime_station['구별'] = np.nan #nan값으로 채운다
crime_station['lat'] = np.nan
crime_station['lng'] = np.nan
반복문과 iterrows()를 활용해서, 구글맵에서 정보 찾고 데이터 프레임에 채우기
for idx, rows in crime_station.iterrows():
#각 경찰서의 정보 찾기
station_name = '서울' + str(idx) + '경찰서'
tmp = gmaps.geocode('서울영등포경찰서', language = 'ko')
#구 이름
tmp_gu = tmp[0].get('formatted_address').split()[2]
#위도, 경도
lat = tmp[0].get('geometry')['location']['lat']
lng = tmp[0].get('geometry')['location']['lng']
#데이터프레임에 넣기
crime_station.loc[idx,'구별'] = tmp_gu
crime_station.loc[idx, 'lat'] = lat
crime_station.loc[idx, 'lng'] = lng
crime_station.head()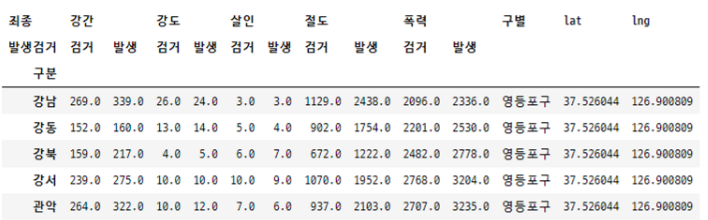
다중 컬럼 바꾸기 → get_level_values( )[ ]
columns.get_level_values(n)[m] n번째 줄, m번째 값을 얻을 수 있음
tmp = [
crime_station.columns.get_level_values(0)[n] + crime_station.columns.get_level_values(1)[n]
for n in range(0, len(crime_station.columns.get_level_values(0)))
]
crime_station.columns = tmp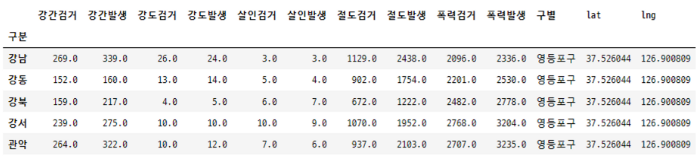
칼럼끼리 나누기 → div( )
#하나의 컬럼을 다른 컬럼으로 나누기
crime_anal_gu['강도검거']/crime_anal_gu['강도발생']
#다수의 컬럼을 다른 컬럼으로 나누기
crime_anal_gu[['강도검거','살인검거']].div(crime_anal_gu['강도발생'], axis=0).head() # axis = 0 가로 연산
#다수의 컬럼을 다수의 컬럼으로 각각 나누기
num = ['강간검거', '강도검거', '살인검거', '절도검거', '폭력검거']
den = ['강간발생', '강도발생', '살인발생', '절도발생', '폭력발생']
crime_anal_gu[num].div(crime_anal_gu[den].values).head()
정규화
- 최고값은 1, 최솟값은 0
- 모든 값들을 가장 큰 값으로 나눠서 정규화한다
col = ['살인', '강도', '강간', '절도', '폭력']
crime_anal_norm = crime_anal_gu[col]/crime_anal_gu[col].max()
crime_anal_norm.head()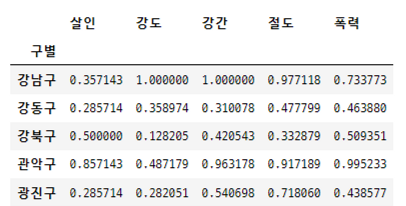
여러 컬럼의 평균을 구해서 컬럼 추가 → np.mean( )
#정규화된 범죄발생 건수 전체의 평균을 구해서 범죄 컬럼 대표값으로 사용
col = ['강간', '강도', '살인', '절도', '폭력']
crime_anal_norm['범죄'] = np.mean(crime_anal_norm[col], axis = 1)
#검거율의 평균을 구해서 검거 컬럼의 대표값으로 사용
col = ['강간검거율', '강도검거율', '살인검거율', '절도검거율', '폭력검거율']
crime_anal_norm['검거'] = np.mean(crime_anal_norm[col], axis = 1)
crime_anal_norm.head()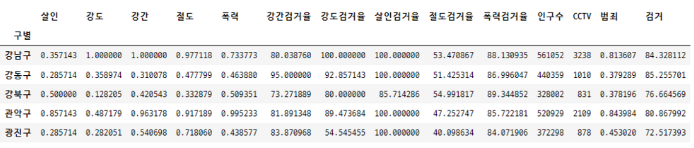
➰ 23일차 후기

어떠한 가정을 검증하기 위해, 데이터를 적절한 방식으로 편집하고 다룬다는 것이 재미있는 듯 하다.
새로운 메소드들과 내용들을 배우다보면, 그 본래 목적은 줄곧 잊혀지게 되고 익숙치 않은 내용들에 학습이 버겁게 느껴질 때가 있기도 하다.
하지만, 이러한 과정이 모두 나의 무기와 도구를 만드는 과정임을 이따금씩 되뇌어야 겠다.
※본 내용은 제로베이스 데이터 취업 스쿨에서 제공하는 학습 내용에 기반합니다.
'제로베이스 데이터 스쿨 > 일일 스터디 노트' 카테고리의 다른 글
| 25일차 스터디노트 / 파이썬 웹데이터 수집하고 정리하기, Beutiful Soup, 네이버금융·위키백과·시카고 맛집·네이버영화 데이터 수집 및 정리 (0) | 2023.02.06 |
|---|---|
| 24일차 스터디노트 / 파이썬 Seaborn, Folium, 지도 시각화, 데이터 시각화 (0) | 2023.02.03 |
| 22일차 스터디노트 / 판다스 자율 학습 - [Do it! 데이터 분석을 위한 판다스 입문] (0) | 2023.02.02 |
| 21일차 스터디노트 / 판다스 - 데이터 시각화, 데이터 경향 표시, 파이썬 프로그래밍 테스트 (0) | 2023.01.29 |
| 20일차 스터디노트 / 파이썬 판다스 - 데이터 훑어보기, 데이터 합치기, matplotlib 기초 (0) | 2023.01.28 |



